No-Downtime Maintenance
I once worked for a company that would simply swap their entire web site with a notice page whenever they need a maintenance window, pretty much like the Twitter whale page but with texts only – not even pictures. Looking back, it was real luxury. Today let’s take a look at the different ways of doing no-downtime maintenance.
The Good Old ‘Reload’ Way
I used to rely on Nginx‘s reload feature to do system maintenance work without system downtime. With Python’s virtualenv, it’s easy to deploy different versions of the same system on the same server. Then all you need to do is simply to update the Nginx config, point it to the new upstream, reload Nginx and you’re done.
This simple method works great as long as you could have multiple versions of your system running at the same time. This way, you could not only test your new codes in the production environment without any user noticing – not necessarily a dark launch but it could be the first step towards it, but also quickly fall back to your old version should anything go wrong with the new one.
But there are times you really want a tiny maintenance window of system downtime to make your day easier, such as when you need to switch to a new master database.
The Dumb Middle Man Way
So the other day I stumbled upon a presentation and a blog by Braintree on how they put redis in the middle of the request-response loop to suspend HTTP requests and gain access to a 30-seconds user unnoticeable maintenance window. Here is the idea of their design:
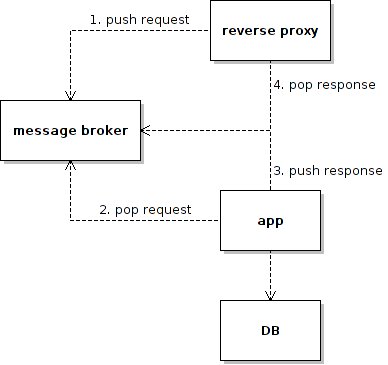
While redis is not a full-blown MQ product – and it never intended to be, its blocking list pop command could be easily used as a MQ service. The reverse proxy (called broxy) is a home-brew Tornado-based python server. The app server (called dispatcher) is a built with Rais / rack. The message payload is in JSON format. Here is a gevent based version of the reverse proxy (nothing special about prototyping on gevent rather than Tornado as eventually they both come down to non-blocking IO with select / epoll / kqueue, just that I am more familiar with gevent):
import uuid
import simplejson as json
import redis
import gevent
from gevent import monkey; monkey.patch_all()
from gevent.event import AsyncResult
from gevent.pywsgi import WSGIServer
_reqs = {}
_r = redis.StrictRedis(host='localhost', port=6379, db=0)
def proxy(environ, start_response):
# register a response handle to a request id
resp_hdl = AsyncResult()
req_id = str(uuid.uuid4())
_reqs[req_id] = resp_hdl
# STEP 1. push request into MQ
env = dict((k,v) for k,v in environ.items() if not k.startswith('wsgi'))
req = {'req_id': req_id, 'env': env}
_r.rpush('request', json.dumps(req))
# wait for response
resp = resp_hdl.get()
# return response
status = '200 OK'
headers = [('Content-Type', 'text/html')]
start_response(status, headers)
return [resp]
def listen_for_response():
while True:
# STEP 4. pop response from MQ
response = _r.blpop('response')[1]
response = json.loads(response)
# retrieve previously registered response handle by request id
req_id = response['req_id']
resp_hdl = _reqs.get(req_id)
if resp_hdl:
resp_hdl.set(response['resp'])
else:
print 'invalid request id'
if __name__ == '__main__':
gevent.spawn_later(1, listen_for_response)
port = 8000
print 'proxy starting at port', port
WSGIServer(('', port), proxy).serve_forever()
And here is the dispatcher prototype:
import redis
import simplejson as json
_r = redis.StrictRedis(host='localhost', port=6379, db=0)
def dispatch():
while True:
# STEP 2. pop request from MQ
req = _r.blpop('request')[1]
req = json.loads(req)
resp = {'req_id': req['req_id']
, 'resp': req['req_id']
}
# STEP 3. push response to MQ
_r.lpush('response', json.dumps(resp))
print 'dispatched.'
if __name__ == '__main__':
dispatch()
In this dispatcher prototype I am simply returning the random request id as response content in a tight loop, nothing fancy here. Depending on the app services running on this app server (dispatcher) being IO bound or CPU bound, a threaded or non-blocking IO based solution is probably the way to go. Or simply run a bunch of app server instances in independent processes across independent servers – probably the most common choice. For this simple demo, let’s keep it simple and stupid. As the point is about the HTTP request suspending mechanism, not specific request processing. But there are actually more to be said about this when it comes to how applicable this design would be in general.
There you are a HTTP request mechanism, simple and effective, especially if you are building web services that are ‘lightweight’ on request and response payload, such as online payment systems. Whenever you need a maintenance window, just stop the app servers (dispatchers) – presumably gracefully with necessary shutdown logic in the dispatcher not shown here. The requests from users could just keep coming in and being piled up as greenlets in the reverse proxy process, together with file descriptors piling up in kernel for select / epoll / kqueue and messages piling up in the message broker. As long as the maintenance window is kept reasonably small, everything should be fine.
But there are more issues to be considered for general web systems.
First is the middle man overhead issue. With every request and response going through the message broker, we’re paying toll to this middle man in our way for each and every request. Depending on the performance of the specific message broker in our production environment and the payload of the requests and responses, the system’s overall response time and throughput might suffer.
Second is the victim issue. If there are other app services provided by the app server that access only other independent backend services, say a KV store or another independent DB service DB-b, then during the maintenance window for DB-a these otherwise unaffected app services would be stopped / suspended too. Let’s call these app services victims of DB-a.
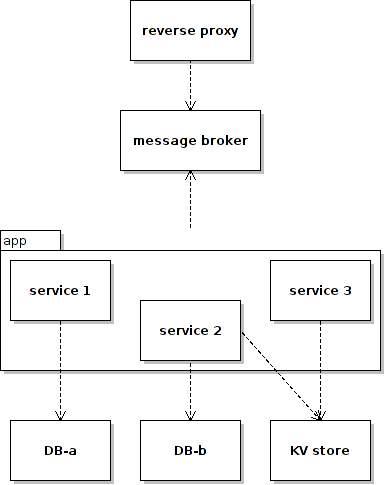
We may try to save these victims from unnecessary suspending by deploying them to different app servers according to what backend services they require. Unfortunately the mapping between our app services and the backend services could be many-to-many and there will be times that DB-a-dependant app services and non-DB-a-dependant app services are both parts of the same sub system – could be a result of DB vertical partitioning for example. And we’d really want or need them in the same app server.
Even if we somehow manage to come up with such a delicate design that allows us to cherry-pick only the affected app servers to be stopped – should the requirement allow it, and we build the dependency management and app server deployment infrastructure smart enough to allow easy future evolution of our system, there is still a question that could be asked. Why are we stopping the app servers while the backend service is what we really need to stop?
The Smart Middle Man Way
Let’s put on our dependency analysis glasses and take a look at the above question. One of the benefits of having a message broker is that it allows decoupling of message producers and consumers, in terms of both technology used to implement them AND the run time status mismatch between them. Put it another way, given a message broker, message producers and consumers do not necessary need to be running at the same time. We should be allowed to stop either the producers and the consumers any time we want without breaking the system.
So let’s change the position of the message broker a little bit, and let the app services and the backend services talk through the middle man.
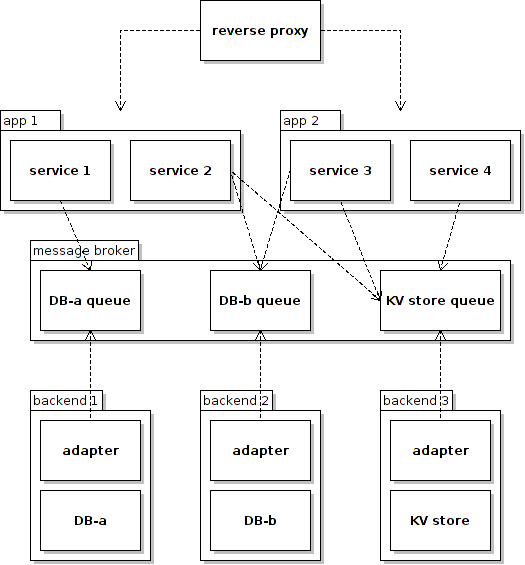
Now the mapping between the app services and the backend services does not matter when it comes to stopping a backend service. And the dependency is maintained by the message broker. We can stop any backend service any time we want without worrying about what depends on what. If we start throwing in more features into the middle man such as conversion of different message format, support for different RPC mechanism, prioritizing and scheduling of workload etc., it will start to look like a ESB architecture.
There will be quit a bit of work down this path, depending on how smart and performant we need our middle man to be. But no matter how performant the middle man could be, it is still a middle man to whom we need to pay toll. And we might just want to keep our design simple and not worry about splitting business logic into an app tier and a backend tier to accommodate this design solely for the sake of no-downtime maintenance. So now let’s back off a little and keep thinking.
The Directory Service Way
Let’s define our problem in the first place again. Given a bunch of app services running against a bunch of backend services – be it RDBMS, KV store, or whatever other services, when any of these backend services needs a maintenance window, we want to suspend only the corresponding app services and hide the maintenance window from our users.
Given that we’re using the non-blocking IO model – and a single-thread / coroutine model as opposed to a multithread / multiprocess one, our app servers should be able to accept and hold on to a large number of concurrent connections as long as resources allow – the middle man is not helping us on this. What the middle man is actually helping is to serve as a channel to convey the signal of a backend service stopping or resuming event – in the form of response message queues. So if we don’t need any other fancy ESB features, we might just get rid of the middle man altogether and use a directory service to convey the event of maintenance.
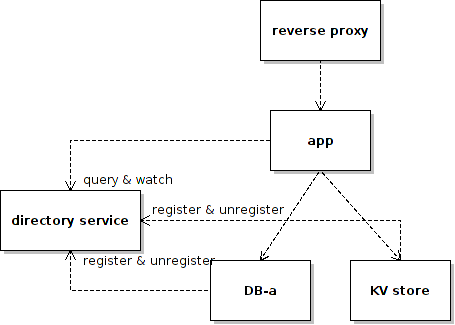
Here is a simple app prototype to show the idea:
import uuid
import simplejson as json
import gevent
from gevent import monkey; monkey.patch_all()
from gevent.event import Event
from gevent.pywsgi import WSGIServer
from kazoo.client import KazooClient
_zk = KazooClient()
_zk.start()
_ready_backend_db_a = Event()
def proxy(environ, start_response):
# check if the required backend service is ready
_ready_backend_db_a.wait()
# start processing request in the good old way
resp = str(uuid.uuid4())
status = '200 OK'
headers = [('Content-Type', 'text/html')]
start_response(status, headers)
return [resp]
@_zk.DataWatch("/backend/db/a")
def master_db_changed(data, stat):
if data:
print 'db a is ready'
# do connection setup / pooling prepartion work here ...
_ready_backend_db_a.set()
else:
print 'db a is not ready'
_ready_backend_db_a.clear()
if __name__ == '__main__':
port = 8002
print 'starting server at port', port
WSGIServer(('', port), proxy).serve_forever()
In this prototype we’re using Zookeeper to provide the directory service, and storing the readiness status of the required DB-a backend service at the ‘/backend/db/a’ directory. Before processing a request, we check a local condition variable (gevent.event.Event) for the readiness of the required backend service, and simply wait for it to become ready if it is not. A watch on this directory allows us to take corresponding action (preparing connections and updating the condition variable) when a relevant event happens, such as the service going offline / online or changing configuration. Since gevent’s synchronization primitives incur merely user space coroutine switching, their impact on performance should not be significantly higher than that of ordinary branch instructions (probably need further quantitative verification though).
Assumptions Revisit
While the directory service way seems promising, it is only considered so under certain assumptions. We’re only trying to deal with scheduled maintenance here, and we’re NOT talking about unexpected backend downtime. Unexpected backend downtime could happen, well, unexpectedly at any moment – either right after the check of readiness passes or in the middle of our transaction, or when we’re trying to commit our transaction. As long as this request processing coroutine is scheduled to run, no other coroutine including the watch one could do anything before this coroutine yields control – collaborative multithreading remembered? So in case of an expected backend downtime, it will just fail, assuming no other fault tolerant logic implemented. It’s the same with the dumb middle man way. But depending on how smart it is, the smart middle man could hide, or even self-heal unexpected backend service interruption. Well, the directory service way could of course do the same sort of fault tolerance work. After all, that’s how Hadoop and Google do it right. But that’s really a big topic and let’s save it for another day. Just bear in mind that we are talking about hiding scheduled maintenance downtime here, NOT fault tolerance in general.
Even with the availability benefit of the smart middle man way, whether it is worth of paying the overhead and accommodating the overall system architecture depends on specific trade-offs mandated by requirement. If we’re talking about ‘making the common cases fast, the corner cases possible’, then the middle man ways might not be the best bet only for the sake of hiding scheduled system downtime, assuming such downtime are way shorter in time span compared with normal uptime. On the other hand, the directory service way is the least obtrusive for the system architecture, and could stay out of the way completely if we want to – either comment out the readiness checking logic or make it a configuration option.
So what are the other ways? And what are the popular ways? Feel free to let me know if I am missing something.